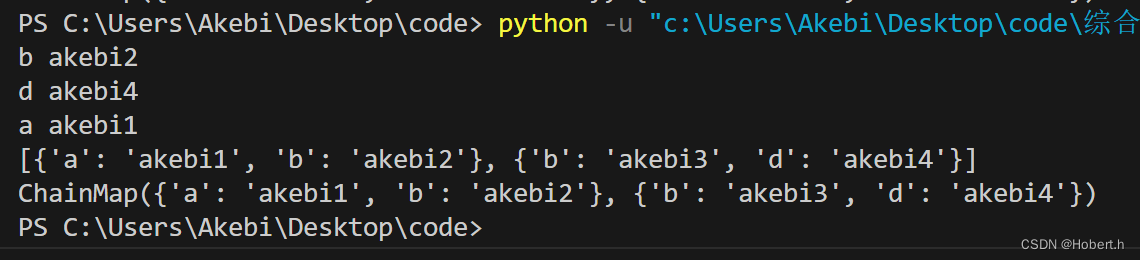
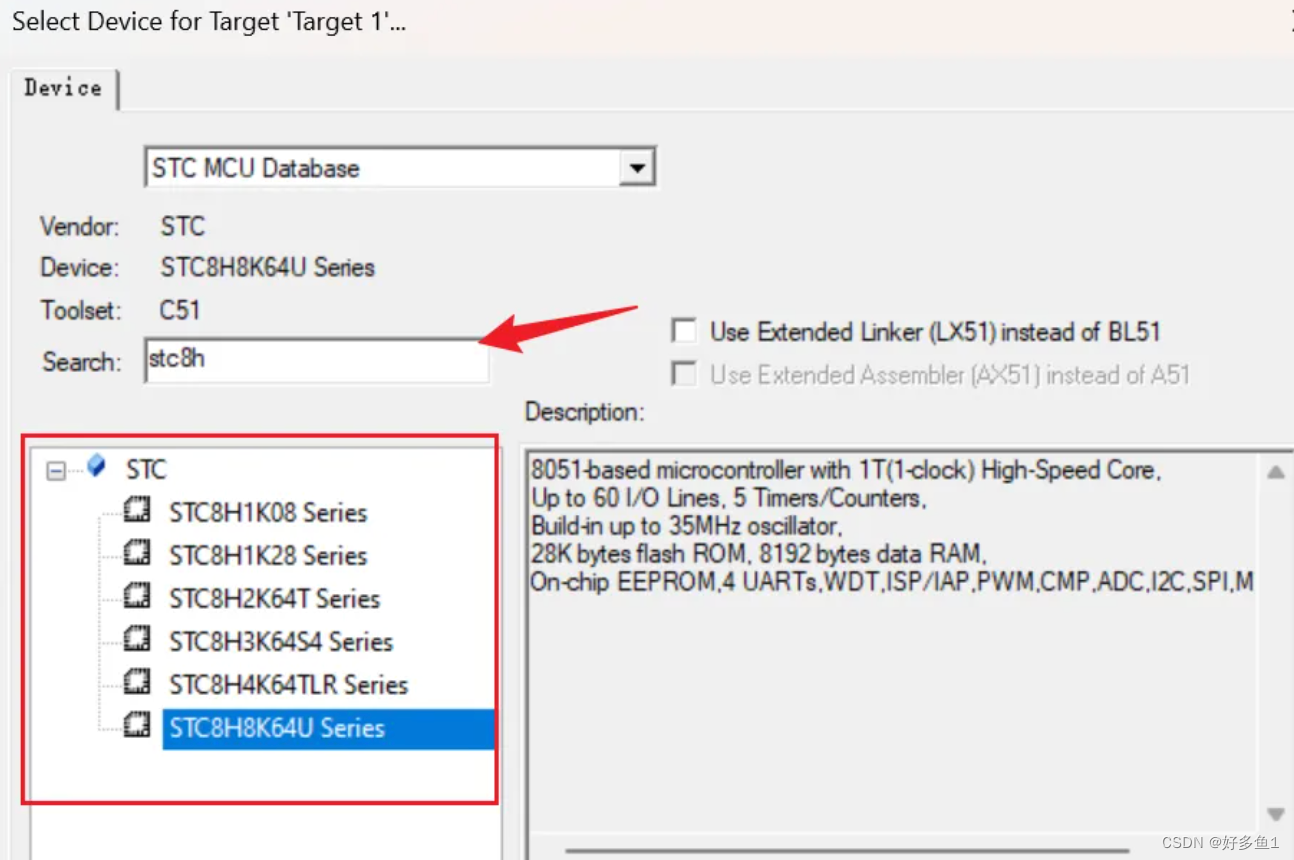
对不同列标识不同信息进行数据读取时
步骤:
1.根据不同列的数据标识的含义和类型,因此需要自定义数据类型
2.使用自定义的数据类型读取数据
有点类似于数据库读取数据操作
例子:
# 1. 以上数据由于不同列数据标识的含义和类型不同,因此需要自定义数据类型
user_info = np.dtype([('name','U10'),('age','i1'),('gender','U1'),('height','i2')])
#print(user_info)
# 2. 使用自定义的数据类型 读取数据,
data = np.loadtxt('has_title.txt',dtype=user_info,skiprows=1, encoding='utf-8')
#data = np.loadtxt('has_title.txt',dtype=int,skiprows=1,usecols=(1,3), encoding='utf-8')
# 注意以上参数中:a.设置类型; b.跳过第一行; c.跳过第一行; d.编码
print(data['age'])
#data
random模块用于生成随机数,下面是一些常用的函数用法:
numpy.random.seed(n) 其中n为任意指定
当我们设置相同的seed,每次生成的随机数相同。如果不设置seed,则每次会生成不同的随机数。
1.np.random.rand 生成一个0到1之间的均匀分布
a = np.random.rand(2,3,4)
2.np.random.randn 返回一个符合标准正态分布的数组。
a = np.random.randn(2,3,4)
3.np.random.randint返回一定范围的一维或者多维整数
numpy.random.randint(low, high=None, size=None, dtype=’l’)
4.np.random.choice从给定的一维数组中随机选择数生成随机数
numpy.random.choice(a, size=None, replace=True, p=None)
a为一维数组类似数据或整数;size为数组维度;p为数组中的数据出现的概率
5.np.random.normal(loc=0.0, scale=1.0, size=None),生成符合指定分布的正态分布
6.np.random.random(size=None),生成符合0到1的均匀分布数组。
7. np.random.ranf(size=None),生成符合0到1的均匀分布数组。
8. np.random.uniform(low=0.0, high=1.0, size=None),生成符合指定均匀分布的数组
9.np.random.shuffle(x),随机打乱数组顺序
binomial() ,二项分布
chisquare(),卡方分布
poisson(),泊松分布
uiform(),均匀分布
normal(),正态分布
numpy的delete函数。delete函数可以删除指定位置的行或列。
new_matrix = np.delete(matrix, 0, axis=0)
函数的第一个参数是要删除的矩阵,第二个参数是要删除的行的索引,第三个参数axis=0表示按行删除